"So we and our elaborately evolving computers may meet each other halfway. Someday a human being, named perhaps Fred White, may shoot a robot named Pete Something-or-other, which has come out of a General Electric factory, and to his surprise see it weep and bleed. And the dying robot may shoot back and, to its surprise, see a wisp of gray smoke arise from the electric pump that it supposed was Mr. White's beating heart."
— Philip K. Dick, The Android and the Human, 1972
Most agent frameworks treat the LLM as a function call, hand the result back to your application, and let your application do everything that should outlive the call. Memory across sessions, personality consistency, tool registration, multi-agent coordination, retry on tool failure: all of it ends up in handlers you write yourself. After enough handlers, the application code is the agent and the framework is a thin shim over the model.
AgentOS puts those concerns inside the runtime. Persistent cognitive memory, optional HEXACO personality, runtime tool forging in a hardened sandbox, six multi-agent orchestration strategies, streaming guardrails, a voice pipeline, and one dispatch interface across the major LLM providers. This post is the announcement that the project is open source under Apache 2.0 and that the public benchmark numbers are real.
The short version: npm install @framers/agentos.
What AgentOS Is
AgentOS is a TypeScript runtime for building AI agents that adapt, remember, and collaborate. Every agent is a Generalized Mind Instance (GMI): a persistent cognitive core with personality traits, episodic memory, and autonomous decision-making.
npm install @framers/agentos
1import { agent } from '@framers/agentos'; 2 3const bot = agent({ 4 provider: 'anthropic', 5 instructions: 'You are a helpful assistant.', 6 personality: { openness: 0.9, conscientiousness: 0.85 }, 7 memory: { enabled: true, cognitive: true }, 8}); 9 10const reply = await bot.session('demo').send('What is AgentOS?'); 11console.log(reply.text);
What Makes It Different
Cognitive Memory
8 neuroscience-grounded memory mechanisms modulated by the agent's HEXACO personality:
- Reconsolidation: memories rewrite each time they are recalled, incorporating new context. Based on Nader et al. (2000) on memory reconsolidation in fear conditioning.
- Retrieval-induced forgetting: retrieving one memory suppresses related competing memories. Based on Anderson et al. (1994).
- Involuntary recall: contextual cues trigger unexpected memory retrieval. Based on Berntsen (2010).
- Ebbinghaus decay: exponential memory decay following the forgetting curve, replicated and validated by Murre & Dros (2015).
- Feeling-of-knowing, temporal gist extraction, schema encoding, source confidence decay: each mechanism implemented in the
CognitiveMechanismsEngine, with trait modulation controlled by HEXACO personality dimensions.
Memory follows a 4-tier hierarchy (working memory, episodic, semantic, observational) that consolidates upward automatically. This approach is grounded in the same ACT-R cognitive architecture principles used by recent systems like Memory Bear and CortexGraph.
Multi-Agent Orchestration
6 coordination strategies for teams of specialized agents:
| Strategy | Description | Use Case |
|---|---|---|
| Sequential | Linear pipeline, each agent refines previous output | Editing chains, translation pipelines |
| Parallel | Fan-out to all agents simultaneously | Research, brainstorming, redundancy |
| Debate | Agents argue positions, synthesize consensus | Decision-making under uncertainty |
| Review loop | Author and reviewer iterate until quality threshold | Content QA, code review |
| Hierarchical | Manager delegates to specialized workers | Task decomposition |
| Graph (DAG) | Dependency-based execution with conditional branching | Complex multi-step workflows |
Agents share memory through the AgentCommunicationBus and coordinate via the AgencyRegistry.
When strategy: 'hierarchical' is paired with emergent: { enabled: true }, the manager LLM gets a spawn_specialist tool alongside its delegate_to_<name> tools. Calling it forges a new sub-agent at runtime via EmergentAgentForge, gates it through EmergentAgentJudge for safety review, and adds the new specialist to the live roster, so delegate_to_<spawned-role> becomes available on the next turn. Bounds via planner.maxSpecialists, planner.maxJudgeCalls, and an optional HITL beforeEmergent gate. See Hierarchical + emergent agent spawning for the worked example.
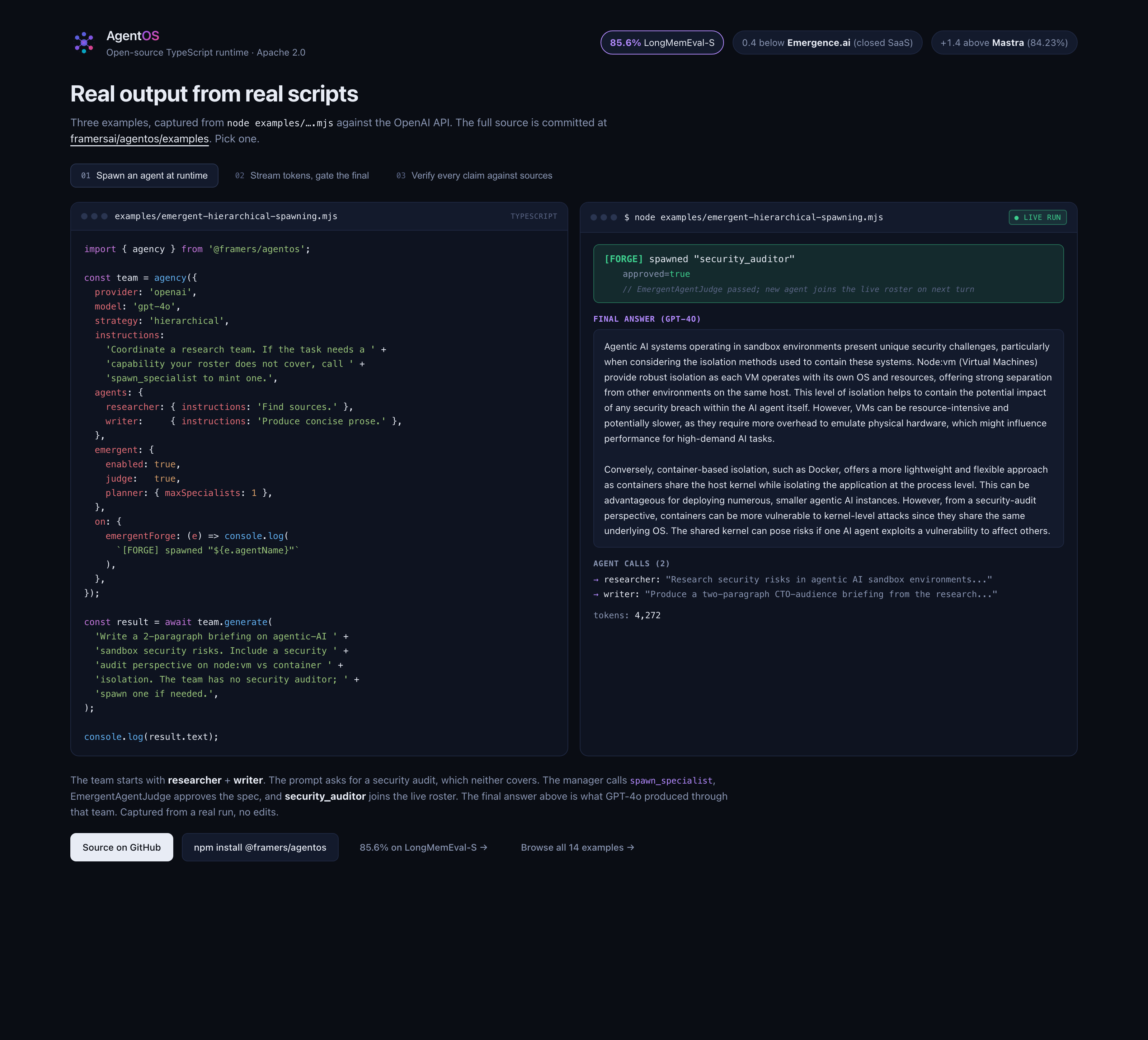
The image above is captured from a real node examples/emergent-hierarchical-spawning.mjs run. The team starts with researcher + writer; the prompt requires a security audit; the manager calls spawn_specialist, EmergentAgentJudge approves the spec, and security_audit_specialist joins the live roster. The [FORGE] line is the moment that happens. Reproduce: node examples/emergent-hierarchical-spawning.mjs after npm install @framers/agentos and export OPENAI_API_KEY=....
Emergent Tool Forging
Agents create new tools at runtime when no existing tool fits the task:
- Compose mode: chains existing tools into pipelines (safe by construction)
- Sandbox mode: generates code in a memory-bounded, time-limited isolation environment
An EmergentJudge reviews safety and correctness before activation. Approved tools promote through 3 trust tiers: session, agent, shared. The EmergentToolRegistry tracks usage and confidence scores.
Production Infrastructure
- 21 LLM providers with automatic fallback chains: OpenAI, Anthropic, Gemini, Ollama, OpenRouter, Groq, Together, Fireworks, Perplexity, Mistral, Cohere, DeepSeek, xAI, Bedrock, Qwen, Moonshot, plus CLI bridges for Claude Code and Gemini CLI
- 37 channel adapters: Telegram, Discord, Slack, WhatsApp, email, webchat, Twitter/X, Instagram, Reddit, Bluesky, Mastodon, and 26 more
- 6 guardrail packs across 5 security tiers from
permissivetoparanoid: PII redaction (4-tier detection: regex + NLP + NER + LLM), prompt injection defense, grounding guards, code safety scanning, topicality enforcement, content policy - Multimodal RAG: 7 vector backends (SQLite to Qdrant), 4 retrieval strategies, GraphRAG with Louvain community detection (Blondel et al., 2008), 10 document loaders
- Voice pipeline: 12 STT providers, 12 TTS providers, VAD, speaker diarization, telephony via Twilio, Telnyx, Plivo
- Graph-based orchestration:
workflow()for deterministic DAGs,AgentGraphfor loops and custom control flow,mission()for planner-driven orchestration - OpenTelemetry observability: opt-in OTEL export, cost tracking, token usage, session audit logs
TypeScript Native
Full type safety with Zod-validated structured output. ESM-first architecture. The TypeDoc API reference documents every public class, interface, and function.
How AgentOS Compares
| Capability | AgentOS | LangGraph | CrewAI | Mastra | VoltAgent |
|---|---|---|---|---|---|
| Language | TypeScript | Python + JS | Python | TypeScript | TypeScript |
| Cognitive memory | 8 mechanisms + Ebbinghaus decay | Checkpoints | Short/long-term | Semantic | Conversation + RAG |
| Personality | HEXACO 6-factor | None | Role descriptions | None | None |
| Channel adapters | 37 | None | None | None | None |
| Voice pipeline | 12 STT + 12 TTS | None | None | None | None |
| Guardrails | 6 packs | Middleware | Basic | None | Module |
| Tool forging | Runtime creation | None | None | None | None |
See AgentOS vs LangGraph vs CrewAI vs Mastra vs VoltAgent for the full comparison.
What we measured (and what we didn't)
AgentOS ships with agentos-bench, an Apache 2.0 memory benchmark suite. We publish bootstrap CIs at 10k resamples on every headline number and the per-cell run JSON for replication. The recent results:
- LongMemEval-S: 85.6% [82.4%, 88.6%] at $0.0090 per correct, gpt-4o reader, 4-second avg latency. Beats Mastra OM gpt-4o (84.2% published) on accuracy at matched reader. Beats EmergenceMem Simple Fast (80.6% measured in our harness, their public reference repo ships with no LICENSE) by +5.0 points at 6.5x lower cost-per-correct. Statistically tied with EmergenceMem Internal's published 86.0%, but Emergence's number comes from closed-source SaaS at emergence.ai/web-automation-api, not a library you can install. AgentOS ships the full architecture under Apache-2.0.
- LongMemEval-M (1.5M tokens, 500 sessions per haystack): 70.2% [66.0%, 74.0%] at $0.0078 per correct with reader-router top-K=5. Competitive with the strongest published M results in the original LongMemEval paper (Wu et al, ICLR 2025, Table 3). At matched reader-Top-5, +4.5 points above the paper's round-level configuration (65.7%) and 1.2 below the paper's session-level configuration (71.4%); 1.8 below the paper's overall best (72.0% at round-level Top-10).
We do not run benchmarks against vendors that don't ship complete standalone runnables. We do not claim X-times-cheaper unless reader model and config match between the two systems being compared. The entire methodology (judges, sample sizes, judge FPR probes, adversarial calibration) is documented in agentos-bench/docs.
This is what an honest benchmark looks like. If something on this list is wrong, file an issue against agentos-bench and we'll fix it or retract the claim.
Get Started
- Documentation
- GitHub
- Discord
- npm
- How to Build a TypeScript AI Agent in 5 Minutes
- Adaptive vs. Emergent Intelligence
- Paracosm launch, the simulation product built on AgentOS
FAQ
Why TypeScript? Most AI infrastructure is Python. Most production application code is JavaScript or TypeScript. The runtime that lives inside an application should match the application's language. AgentOS does. The Python interop story is via the API server (REST/SSE) or via JSON Schema-generated types from the artifact schema.
Is AgentOS a LangGraph alternative? It's an alternative if your job is "build an AI agent with memory and personality and tools." It is not an alternative if your job is "compose Python research code into a workflow." Different jobs. We have a head-to-head comparison post with honest-cost-rule applied.
Does AgentOS lock me into a specific LLM? No. 21 provider adapters ship; you can add yours in ~50 lines if it's not in the list. The provider abstraction is decoupled from the agent abstraction.
What's the deal with HEXACO personality? It's optional. Pass personality and the runtime biases retrieval, decision routing, and tool selection by the trait vector. Don't pass it and the runtime acts personality-neutral. We don't make HEXACO the centerpiece because not every agent needs it; we just make it work cleanly when you want it.
Is the cognitive memory feature the same as RAG? No. RAG retrieves documents. Cognitive memory is a layered system covering short-term context, episodic memory (events with time and emotion encoding), semantic memory (facts and relationships), and a Ebbinghaus-style decay model for forgetting. RAG is one of the retrievers cognitive memory composes with. Read Cognitive Memory Beyond RAG for the deeper version.
Can AgentOS run agents that talk on the phone? Yes. The voice pipeline (12 STT providers, 12 TTS providers) plus telephony adapters in the channels system gets you a voice agent that runs as a phone call. We have a case study with Wilds.ai on the companion side of the same stack.
What about safety? Six guardrail packs ship: topicality, ML classifiers (toxicity / prompt-injection / NSFW), grounding (NLI), PII redaction, code safety (static analysis), and skills (curated SKILL.md execution). Each has its own README in the packages/agentos-ext-* tree.
Is this production-ready for X? Define X. We don't publish a generic "production-ready" label because the answer depends on what you're shipping. We do publish concrete benchmark numbers, concrete safety posture, and concrete provider compatibility. Read those, judge for yourself, file issues when we miss.
Apache 2.0 licensed. Built by Manic Agency / Frame.dev.